
Taming LLMs - Chapter 1: The Evals Gap
If it doesn't agree with experiment, it's wrong.

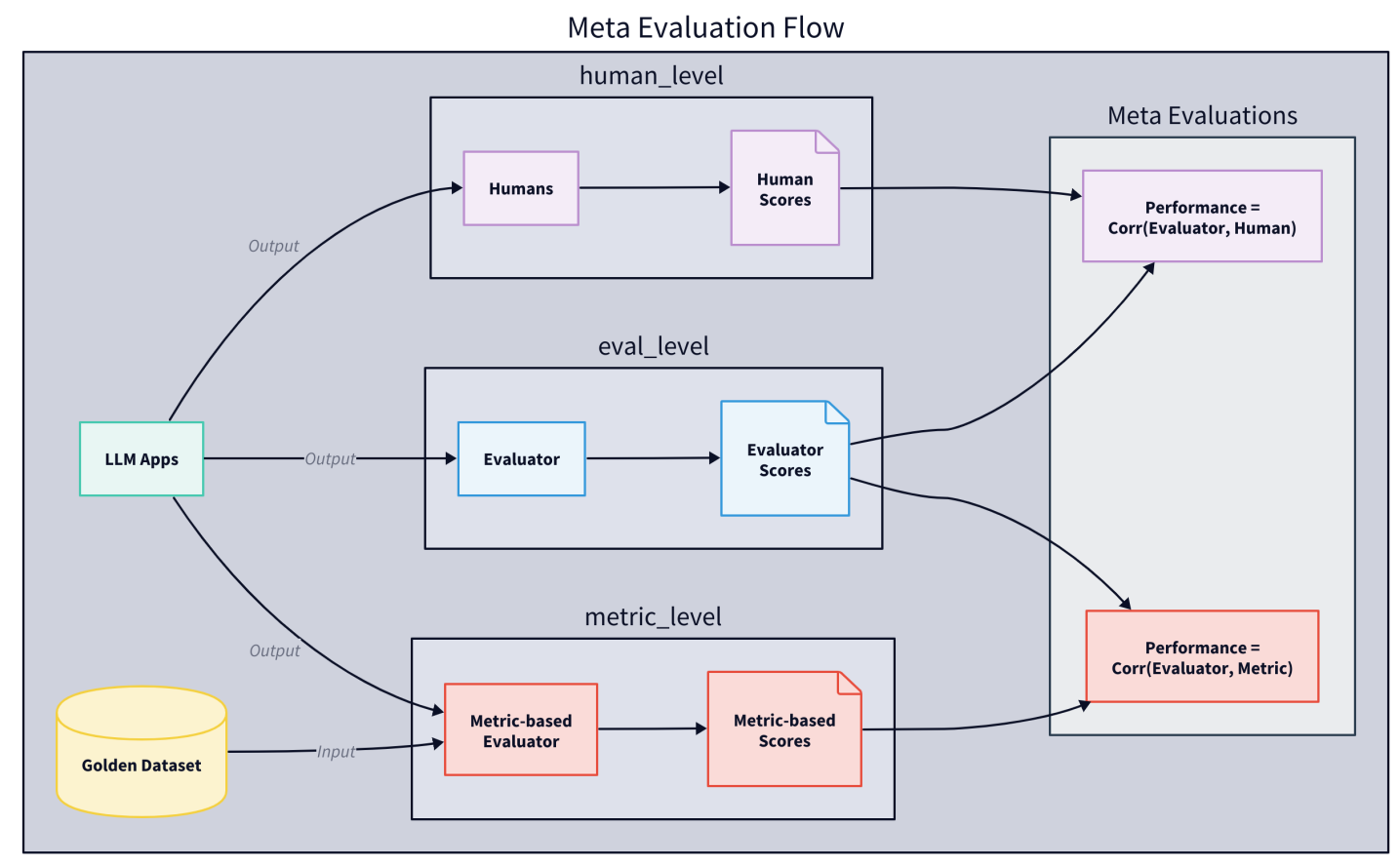
Chapter 1: “The Evals Gap” of the book Taming LLMs is now available for review.
Visit github repo to access Chapter in the following formats:
web and
python notebook formats.
The pdf format is recommended as it contains the highest quality copy.
Please share feedback before Jan 13th via one of the following:
Open an Issue in the book’s github repo
Chapter content:
This chapter explores the critical "evaluation gap" between traditional software testing approaches and the unique requirements of LLM-powered applications, examining why traditional testing frameworks fall short and what new evaluation strategies are needed.
Through practical examples and implementations, we investigate key aspects of LLM evaluation including benchmarking approaches, metrics selection, and evaluation tools such as LightEval, LangSmith, and PromptFoo while demonstrating their practical application.
The chapter emphasizes the importance of developing comprehensive evaluation frameworks that can handle both the deterministic and probabilistic aspects of LLM behavior, providing concrete guidance for implementing robust evaluation pipelines for LLM-based applications.
I hope you enjoy the reading as much as enjoyed writing it. Please share comments particularly pertaining to clarity, relevance and scope. I still have time to make fixes before February 2nd’s official release.
All reviewers will be acknowledged in the book.
—
Thársis
